
At Gigs, we designed our API to be easy to use and understand. We built it around the concept of resources, their relationships, and the actions you can take with them. A key part of making that system work smoothly is how we identify those resources. We wanted a format that was not just easy for machines to read, but for humans too.
We identified that the ideal ID format would:
Be sortable in time to paginate resources efficiently
Be hard to guess to prevent discovery attacks
Describe the resource type to help troubleshooting issues
Identify the customer it belongs to in order to enable sharding
We couldn’t find a standard format that could meet all these requirements, so we decided to build our own, drawing inspiration from the existing ULIDs and the Stripe Object IDs.
The Challenge
To understand some of the design decisions that went into designing this ID format, we need to understand where we started. We originally decided to use ULIDs as the ID format for all our resources. ULIDs, in short, are 128bit long IDs that are composed by a timestamp and a random value and encoded as a 26 character long string in Base32 Crockford.
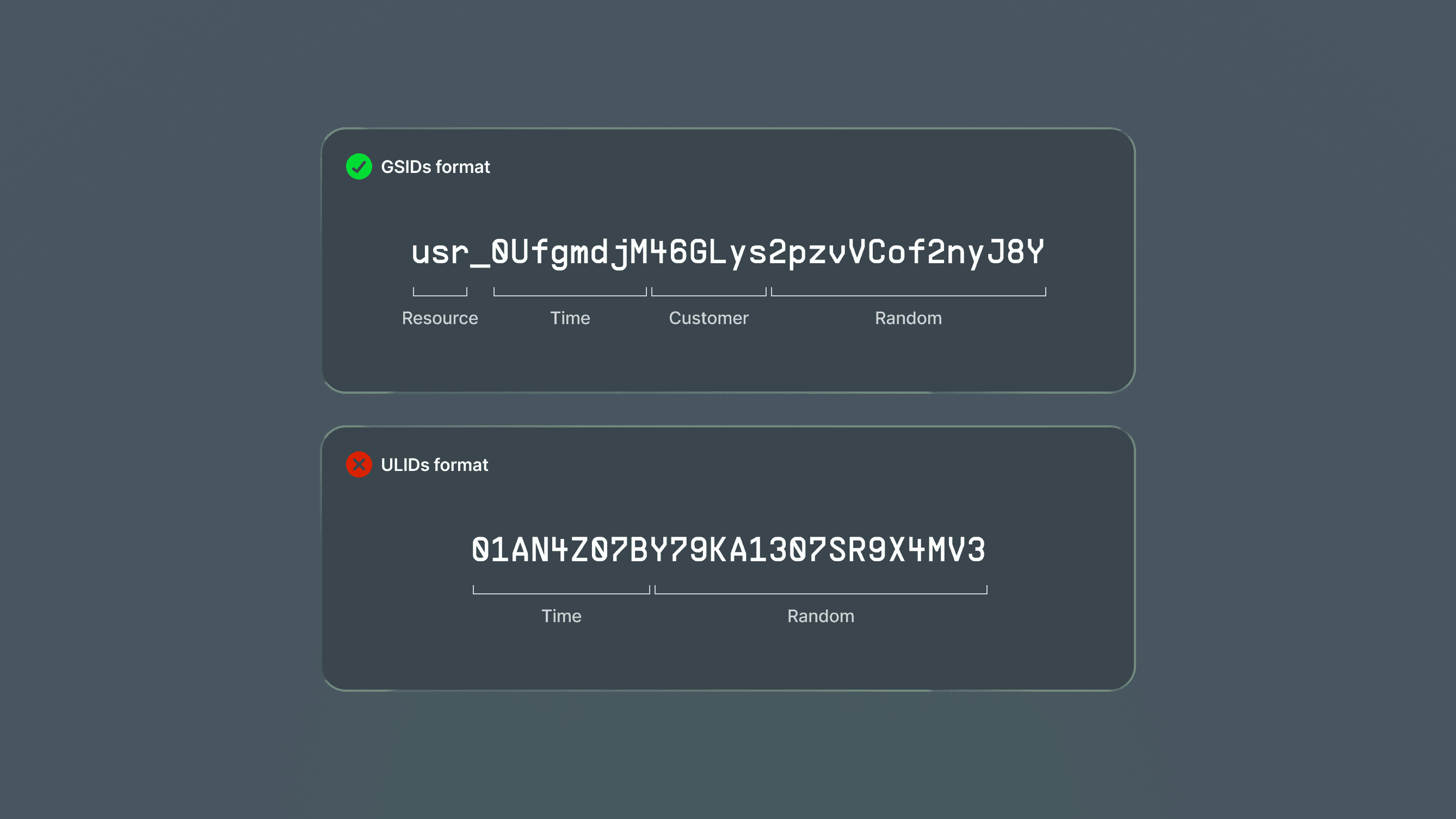
01AN4Z07BY79KA1307SR9X4MV3
└────────┘└──────────────┘
Time RandomWhile this ID format solved most of our requirements, it had a few limitations. You couldn't easily tell the resource type an ID referred to or which customer it belonged to. We wanted to improve the format, but we faced a major challenge: migrating all existing IDs, which were already used as primary and foreign keys across our databases, without causing any downtime or disruption to the system.
Designing GSIDs
Our custom ID format, called GSIDs (short for Gigs IDs), was designed to be easily converted to ULIDs and maintain all their properties, but still encode the resource and customer when represented as strings. GSIDs are generated from the following components:
3 lowercase characters resource prefix
48 bits Unix timestamp in milliseconds
32 bits customer namespace
80 bits random value
These components are represented in text encoded as Base62, using an underscore to separate the resource prefix. We decided to use this encoding instead of Base32 as it allows us to represent more bits per character, keeping the ID shorter, while still being easy to read for humans and safe to use in URLs.
usr_0UfgmdjM46GLys2pzvVCof2nyJ8Y
└─┘ └──────┘└────┘└────────────┘
Resource Time Customer Random
For the same reason, we dedicate only 8 characters to the timestamp part, which is less than the characters required to encode 48 bits but enough until the year 8888, allowing us to save an extra character.
Conversion to ULIDs
The easiest way we could think of migrating all our IDs to use this new format was to avoid having to migrate them at all. When stripping the GSIDs from the resource prefix and the customer namespace, they have exactly the same binary representation as ULIDs. Because each resource is stored in a separate table and the data for each customer in a separate database shard, this meant we could build tooling that constructed GSIDs from the existing binary ULIDs on read, without having to rewrite them.
With this tooling we could ensure backward compatibility: our API would accept requests using ULIDs or GSIDs indistinctly, and we could decide when to render the existing IDs as GSIDs on responses to avoid breaking existing integrations. This allowed us to deploy the new format without causing any downtime.
Benefits
Apart from the ease of deployment in our particular situation, GSIDs maintain all the good properties that ULIDs have and add a few more of their own:
Human-readable
Prefixing the IDs with the resource types, avoiding any special symbols and keeping them short ensures that humans can tell them apart at first glance.
Namespaced
Storing a customer reference in the ID makes it easy to determine which customer a resource belongs to, allowing us to resolve the correct database shard without additional lookups.
Sortable in time
Encoding the timestamp before the random value makes them sortable in time naturally, down to the same millisecond. This not only makes it trivial to implement cursor-based pagination, but also improves the data locality.
Highly portable
Keeping the text and the binary representations sortable in time ensures that these IDs can be used in any system that supports strings and still maintain all their properties.
Informationally dense
Choosing Base62 instead of Base32 like ULIDs or Base16 like UUIDs allows us to encode more bits per character, keeping the IDs shorter.
Copy-paste friendly
Using the underscore instead of the hyphen as a separator makes it possible to select the whole ID by double clicking in most browsers. You can try_it and see-it yourself!
Conclusion
We spend a lot of time thinking how to make our API easy to use, and GSIDs are a small part of that. While computers do not generally care about how IDs look and feel, humans do. They are a fundamental part of the system to consider when talking about the usability of an API.
GSIDs were designed specifically with our use case and situation in mind, and we think that things like the customer namespacing or the binary compatibility with ULIDs don’t apply to everyone. For this reason, we do not plan to open source them.
We hope you found this post inspiring and it helped you see ID formats in a new light. Whether you take some of these ideas and build your own on top of ULIDs or KSUIDs like we did, or adopt a complete solution like Type IDs instead, thinking carefully about your IDs is worth the effort.


